The phrase “information architecture” was coined—or at least was brought to wide attention—by Richard Saul Wurman,
a man trained as an architect who is also a skilled graphic designer
and the author, editor, and/or publisher of numerous books that employ
fine graphics in the presentation of information in a variety of fields.
In the 1960s, early in his career as an architect, Wurman became
interested in how buildings, transport, utilities, and people worked
together and interacted with one another in urban environments. This
spurred his interest in how information about urban environments could
be gathered, organized, and presented meaningfully to assist architects,
urban planners, utility and transport engineers, and especially people
living in or visiting cities. The similarity of these interests to the
concerns of the information profession is apparent. When a building
architect designs a building that will serve the needs of its occupants,
the architect must
Ascertain the needs of those who will occupy the space and how they will use it
Organize the needs into a coherent pattern that clarifies their nature and interactions
Design a building that will—by means of its rooms, fixtures, machines, and layout—meet those needs
In short, Wurman developed the following characteristics for information architecture.
The organization of the patterns inherent in data, making the complex clear
The creation of the structure or paths to the information that allow others to find the knowledge
Peter Moreville and others expanded Wurman’s thinking about information architecture to include the following elements.
The combination of organization, labeling, and navigation schemes within an information system
The structural design of an information space to facilitate task completion and intuitive access to content
An
emerging discipline and community of practice focused on bringing
principles of design and architecture to the digital landscape
Information architecture
directly impacts the user’s experience of how he consumes and manages
information when working. Information architecture is not just an
abstract, theoretical exercise. Jesse James Garrett developed the
elements of the user experience within a website design context,
connecting what is often seen as an unnecessary exercise to the
day-to-day work of most users. But his elements, shown in the following list, are easily transported to the use of information generally.
User needs and site design
Functional and content requirements
Interaction design and information architecture
Interface and navigation design
Visual design
Donna Mauer’s
ideas about the main elements of an information architecture incorporate
business needs, user needs, and content design. Where those three elements overlap is where you’ll find your information architecture (Figure 1).
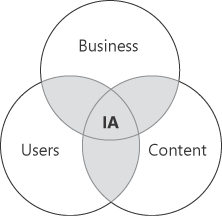
To summarize this
discussion, there is no clear consensus on what an information
architecture is. Moreover, many confuse information architecture with
the following.
Although all of these
elements are components of an information architecture, they are really
not the same as an information architecture. For example, the design of a
user interface is merely the presentation layer of the information.
Interface design doesn’t describe how information is hosted and tagged.
Hence, from the viewpoint of the authors, an information architecture
(IA) is the art and science of structuring and organizing information systems that support business goals and objectives. The only thing you are doing when you construct an IA is specifying the systems that will hold the data that support the business. Within the IA, a content taxonomy (called an operational taxonomy in Figure 2)
will provide the organization of the various types of content, relative
to the business needs, user needs, technology support, and
relationships between the various types of content.
Thus, you first need to
understand what the business does and how the business really works
before you can design an information architecture that will work
successfully for that business. Without understanding what the business
does—its core activities—it is difficult to know what systems (broadly
speaking) will be needed to support the information the business will
need to be successful. You may think that you should start by outlining
all of the various types of information and work your way back to the
systems. But this method can cause you to look at departmental or
divisional information types as equivalent to enterprise-level
information. If you first define the global systems based on the major
activities of the company, it will help you organize the information
within the systems based on how users interact with both the system and
the information itself.
Note:
In some organizations, the
enumeration of systems alone is not sufficient because these
organizations are highly process-based. Hence, these organizations would
do well to include how the systems interact and how (generally
speaking) information moves between systems as part of their overall IA.
Here is a
suggested information architecture methodology that builds on these
principles while emphasizing the business needs that form the foundation
for the architecture when applied to an environment in which SharePoint
2010 is being implemented. Figure 9-4 illustrates this model.
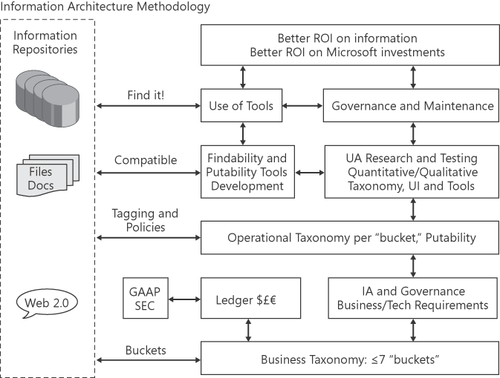
The following sections discuss this taxonomy.
Note:
A taxonomy
refers to a hierarchy or organization of objects that will likely
include synonyms, equivalencies, parent/child relationships, and
metadata. In contrast, a folksonomy
can be thought of as a “free-form” method of describing data without a
hierarchy or an organization of terms from which to draw metadata
values.
1. Business Taxonomy
The development of a business
taxonomy is different than the development of a taxonomy for content.
Recall that a taxonomy is nothing more than an organization of objects.
When you talk about how a business is organized, you need to think in
terms that are different from the company’s organizational charts.
Note:
MORE INFO For more information about the development of a business taxonomy, visit http://sharepointplan.com.
A business taxonomy can be
thought of as containing seven or fewer “buckets.” These buckets hold
the organization’s functions and values. Every organization has broad
categories or buckets into which all of their activities fall. For
example, every organization deals with money, so there will usually be
one bucket called Money. Most organizations have customer service, which
can form a second bucket. Some organizations have research and
development departments, whereas others might not have in-house research
capacity that forms a major part of their business.
Most software
development companies would have—at a minimum—the following buckets:
Money, Learning and Development, Production, Customer Service, and Sales
and Marketing. Dividing the functions of a business like this can give
you a handle on what parts of the business need their own operational
taxonomy. Keep in mind that the business buckets do not necessarily
represent the organizational chart.
2. Information Architecture, Governance, and Requirements
In this section, you will learn
about how to plan and build an overall information architecture. It need
not be detailed, and in most organizations, it will not be specific to
divisions or departments unless those divisions require unique systems
to host their unique information. For example, a research company such
as 3M or Dow Chemical will have very different types of data among their
various divisions, some of which is hosted by information-specific
software programs. When this is the case, the IA will need to be built
at the divisional as well as the enterprise levels.
Also, be aware that some IA
will be process-based, such as when a system doesn’t hold only static
data, but instead hosts data and a process and moves that data through
the process. Microsoft’s Customer Relationship Management (CRM)
program would be a good example. A lead is turned into an opportunity,
which is turned into a quote, which is turned into an order, which is
turned into an invoice. All the while, the data for the customer and
opportunity are held in CRM and moved through the process. In addition,
different types of data are added as the customer is moved through the
process. Although SharePoint 2010 can be configured to be a
process-based platform, it is configured out-of-the-box as a
non-process-based platform.
So, your IA should include
details about both types of data hosted in each system as well as
specifics about any mission-critical processes and which systems will
host those as well.
Whereas an IA is
focused on systems, information architects organize content and design
navigation systems to help people find and manage information better.
2.1. Governance
Governance is an inherent part
of how the IA is constructed, because each system will require the
development of engagement rules with that system. In short, governance
includes the rules that determine how users interact with the systems
and information
and it also establishes who will enforce the rules—and make changes to
the rules when needed. Without the second part—enforcement and
management—governance is essentially useless. It is like a sporting
event that has rules but no officials to enforce the rules.
Note:
BEST PRACTICES
Some organizations create long governance documents that are difficult
to read. However, a best practice is to do the opposite and not place a
rule in the governance document unless it adheres to the following
guidelines.
In a recent survey of 186
SharePoint deployments, fully two-thirds of the respondents were either
unhappy or only partially happy with the state of their governance. The
reasons for this were clustered around a lack of ability to enforce
governance rules, lack of staffing to support the governance effort, and
lack of upper management support for governance in general. These and
other reasons continue to hamper SharePoint implementations as
organizations grapple with the “people” side of their implementation.
Understanding how information should be managed and how users should
interact and utilize the features in SharePoint is essential to
achieving a successful implementation.
2.2. Requirements
Every SharePoint 2010
deployment should be based on strong business requirements that both
define the problem and outline the desired solution. Requirements are
not something that you can just ignore and then expect to retrofit into
the feature set of SharePoint 2010. They should be developed in a
technology-agnostic environment and then turned into technical
requirements before you select a software package to support those
requirements.
It’s pretty obvious that Microsoft has done a good job of building
a software product whose features meet the needs of many businesses and
their business problems; otherwise, SharePoint 2010 wouldn’t be selling
well and you wouldn’t be reading this book. But it’s also obvious that
many companies implement SharePoint 2010 in an impulsive manner that
doesn’t account for the mapping of business requirements to the use of the technology.
Note:
A common mistake committed
when people write business and technical requirements is to take the
feature set of SharePoint 2010 and downstep it into a specific
organization’s requirements. In other words, because the feature is
available in the software product, you decided to build a business
requirement and technical requirements that will require that feature.
Don’t do this—requirements are written to describe what is needed to
solve a business problem, not to ensure a particular software product is
selected for implementation.
3. Putability and Operational Taxonomies
In the following sections,
you will learn how to create the taxonomy for each bucket in your
business taxonomy. In most environments, you will not have any more than
two to four metadata fields that you want attached to each document or
record across the enterprise. But within each bucket, you’ll have a more
robust taxonomy that will be flexible and unique to that part of the
business. For example, referring back to Figure 9-4,
you’ll notice that there is a place for the accounting, or the “Money”
part of your business. Because this area of your business is already
described and regulated by generally accepted accounting principles (GAAP), the U.S. Securities
and Exchange Commission (SEC), and other regulations, a taxonomy
already exists for this part of your business if you care to use it.
Don’t re-invent the wheel
when creating your taxonomy. Be sure to check out standard taxonomies
that already exist for the different functions in your organization; you
may find that you can use one or more of these with modifications.
These standard taxonomies are a great place to start when planning your
unique taxonomies.
3.1. Dublin Core
In its early days, the Dublin Core Metadata Initiative (DCMI)
outlined a 15-element core set of metadata that they thought could be
applied to any record or page anywhere in the world. These elements are
outlined in RFC 5013, ANSI/NISO Standard Z39.85-2007, and ISO Standard 15836:2009.
This standard of metadata is reflected in the Dublin Core content type
that ships out-of-the-box with SharePoint 2010. If you need a place to
start building your operational taxonomies, take a look at the Dublin Core. The following 15 elements make up the core set of metadata.
Title
Creator
Subject
Description
Publisher
Contributor
Date
Type
Format
Identifier
Source
Language
Relation
Coverage
Rights
Note:
MORE INFO You can learn more about the DCMI at http://www.dublincore.org.
3.2. Darwin Information Typing Architecture
The Darwin Information Typing Architecture (DITA) is an XML-based architecture for authoring, producing, and
delivering information. To date, its main applications have been in
technical publications with a focus on information interchange and
reuse. DITA focuses on reuse with a topic-based
core set of metadata. A common misconception is that DITA defines
everything you could possibly want in content models. In reality, DITA
defines only base models, and its developers expect that you will create
your own topic types to meet your own information needs.
The DITA architecture defines four layers.
Delivery context The processing and delivery context
Typed topic structures The formal content structure
Common structures Metadata and table structures that can be shared with any topic
Shared structures Content models for structures that can be used in all documentation
Note:
MORE INFO You can learn more about DITA at http://dita.xml.org.
3.3. Other Taxonomies
There are other types of base
taxonomies that you might want to leverage, given the type of
information that you’re trying to organize. Following are some examples
of existing taxonomies.
DocBook Popular content model for software documentation
SCORM An XML-based method of representing course structures
IPSV
Integrated Public Sector Vocabulary, an “encoding scheme” for
populating subject elements of metadata, a standard developed in the
United Kingdom
OpenDocument Format An XML-based file format specification for Microsoft Office documents
XMP (Extensible Metadata Platform) Adobe-led labeling technology that allows you to embed data about a file into the file itself
NewsML A method designed to provide a media-type-independent, structural framework for multimedia news
There are also some predefined vocabularies that you might be able to leverage as you create your taxonomy.
Gale Accounting Thesaurus (Gale Group, Inc.)
European Education Thesaurus (Eurydice European Unit)
ACM Computing Classification System (Association for Computing Machinery)
http://taxonomywarehouse.com
Referring back to Figure 2, you’ll see that the operational
taxonomy layer is where you need to develop your tagging and putability
policies. Based on the old “garbage in, garbage out” principle, you can
understand that how information goes into SharePoint 2010 will directly
impact how it comes back out. In this part of your information
organization project for SharePoint, be sure that you take the time to
understand not only the taxonomies and their values for the data you’re
describing, but also the policies that users must follow and the ways
that the information repositories will accept the tagging of data.
4. Usability and Tool Development
Next, you need to develop the user interfaces and tools necessary for both putability
and findability. An example of a findability tool would be a custom
advanced Web Part that exposes key metadata for a multi-keyword query.
An example of a putability tool would be a custom interface that allows a
user to input metadata when a new document is first saved.
Content types can be viewed as putability tools, whereas search Web Parts would be considered findability tools. Table 1 offers some additional ideas on how SharePoint 2010 tools can be leveraged. This is not an exhaustive list.
Table 1. Putability and Findability Tools
| TOOL/FEATURE | PUTABILITY | FINDABILITY | BOTH |
|---|
| Sites directory | | | X |
| Managed paths | | X | |
| Content types | X | | |
| My Site personalization | | X | |
| Audiences | | X | |
| Scopes | | X | |
| Records center | | | X |
| Site columns | | | X |
| Folders | | X | |
| Metadata Managed Service | X | | |
| Search Web Parts | | X | |
| Indexing | | X | |
| Breadcrumb navigation | | X | |
| URL and site design | X | | |
The tools
that you utilize, whether out-of-the-box or customized, will depend on
why you are implementing SharePoint 2010 in your organization, the type
of data that will reside in SharePoint 2010, and the outcomes of your
IOPS effort. Best practice is to utilize the tools and Web Parts that
ship with SharePoint 2010 before writing any custom code. Moreover, if
you can purchase third-party code instead of developing it yourself,
that is also a smart choice.
5. Use of SharePoint and Maintenance
At this point, you’re ready to
roll out SharePoint 2010 and have your company’s employees use the
product. As part of your rollout plan, you’ll want to ensure that
employees have been trained well and that you’re following regular
procedures to enforce the governance plan. Also, be prepared to find
that as your information grows, changes, and evolves, your IA and
taxonomies will have to adjust as well. This is an ongoing, but not a
constant, effort.